17,562 reads
16 SQL Techniques Every Beginner Needs to Know
by Mike ShakhomirovFebruary 11th, 2023


















Too Long; Didn't Read
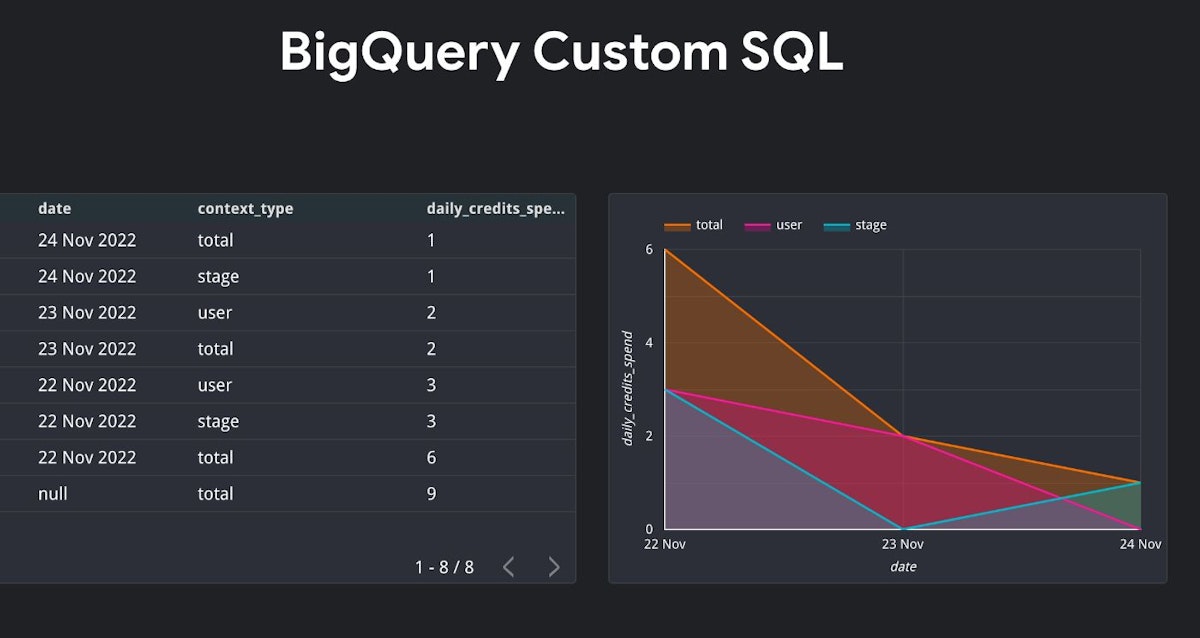
This blog post explains the most intricate data warehouse SQL techniques in high detail. Use BigQuery standard SQL dialect to scribble down a few thoughts on this topic.


Mike Shakhomirov
@datamike

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
Languages











THIS ARTICLE WAS FEATURED IN...



RELATED STORIES




10 FinTech Trends in 2021 [Part II] #fintech
Invalid Date